AI编程核心概念
掌握AI编程的关键术语和核心原理,为高效使用AI编程工具打下坚实基础
学习路径: 基础术语 → 提示词技巧 → 核心原理 → 实战应用
AI编程基础术语
掌握这些术语,是理解AI编程的第一步
1. 提示词(Prompt)
提示词是你向AI下达的编程指令或需求描述。它不是什么神秘的咒语,而是你与AI沟通的桥梁。提示词的质量直接决定了AI生成代码的准确性。
❌ 模糊的提示词
"生成一个接口"AI不知道你要什么类型的接口,用什么框架,返回什么数据...
✓ 精准的提示词
"生成一个基于Go Gin框架的用户登录接口,接收JSON格式的用户名和密码,返回包含token的JSON响应"AI清楚知道要生成什么,直接输出可用的代码
2. 提示词工程(Prompt Engineering)
提示词工程就是优化提示词的方法。你不需要懂AI的底层技术,只要掌握一些简单的优化技巧,就能让AI生成更贴合你需求的代码。
核心技巧
- •明确需求:清楚告诉AI你要做什么
- •补充约束:指定技术栈、版本、风格等限制
- •给出示例:提供参考代码或期望的输出格式
3. 生成式AI(Generative AI)
生成式AI是能自主生成代码、文本等内容的AI模型。它不需要你手动编写全部代码,而是根据你的描述自动生成。这是AI编程的核心支撑,也是区别于传统编程的关键。
代码生成
Bug修复
代码优化
4. 代码补全(Code Completion)
代码补全是AI编程最基础、最常用的功能。当你输入代码时,AI会自动补充后续的代码片段。这能大幅提升编码效率,减少重复劳动。
例如,当你输入:
def calculate_sum(numbers):
total = 0
for num in numbers:
total += num
returnAI会自动补全为:
def calculate_sum(numbers):
total = 0
for num in numbers:
total += num
return total5. 代码重构(Code Refactoring)
代码重构是指AI在不改变代码原有功能的前提下,对代码进行优化,让代码更简洁、可读性更强、可维护性更高。
常见应用场景
- • 简化冗余代码
- • 优化变量命名
- • 提取重复逻辑为函数
- • 改进代码结构
6. 上下文(Context)
上下文是你提供给AI的所有相关信息,包括需求描述、已有的代码、对话历史等。清晰的上下文能帮AI精准理解你的编程需求,避免输出偏离预期。
💡 实用建议
在让AI生成代码前,先提供相关的代码片段、项目结构、依赖配置等信息,这样AI生成的代码会更贴合你的项目实际。
7. 模型适配(Model Adaptation)
不同的AI模型擅长的编程语言和应用场景不同。选择合适的模型能大幅提升编程效率。
通用模型
适配多场景,通用性强,如GPT-4、Claude 3
编程专用模型
聚焦编程场景,输出更精准,如Codex、StarCoder
8. Token(令牌)
Token是AI阅读和处理文本(包括代码)的最小单元。它既不是单个汉字,也不是完整词语,而是AI计费和控制输出的核心依据。
Token换算
- • 英文:1个Token ≈ 0.75个词
- • 中文:1个汉字 ≈ 1.5-2个Token
- • 代码:空格、缩进、换行都会占用Token
💡 为什么重要?
Token直接关联AI工具的计费逻辑。超出额度会触发截断警告,掌握这一点能更好控制成本和输出长度。
9. 上下文窗口(Context Window)
上下文窗口可以理解为AI的"即时工作记忆"容量。就像把你的代码和相关文档摊在桌面上,桌面的大小决定了能同时摆放的内容多少。
⚠️ "中间丢失"现象
在长对话、长代码场景中,AI最容易忽略中间部分的信息。这就是AI有时会"忘记"前文内容的核心原因。
实用技巧
学会简单估算自己的项目代码是否超过上下文限制,能有效规避记忆溢出、输出偏离的问题。
提示词的核心技巧
掌握这些技巧,让AI生成更精准的代码
系统提示词 vs 用户提示词
理解这两者的区别,能帮你更好地控制AI的输出行为。
系统提示词
给AI"定规矩、划边界",设定AI的角色和行为准则
"你是一个严谨的Go后端工程师,代码需符合Go 1.21版本规范,遵循项目代码风格"用户提示词
你给AI的具体编程任务指令
"生成一个基于Gin框架的用户登录接口代码"💡 实际应用
IDE AI插件(如Cursor Rules)的核心逻辑就是提前预设好系统提示词,规范AI的输出风格,再结合你输入的用户提示词,高效完成编程任务。
结构化指令三要素(CRI模型)
一个好的提示词应该包含这三个核心要素,让AI能够准确理解你的需求。
给AI提供完成任务所需的相关信息
项目使用React 18 + TypeScript,组件位于src/components目录明确指定AI的技术栈版本和代码风格偏好
使用Python 3.10语法,遵循PEP 8规范,添加类型注解清晰告诉AI你的核心需求,明确区分任务类型
生成一个用户认证组件,包含登录表单和错误处理负面约束的力量
有时"告诉AI不要做什么",比"告诉它做什么"更能精准把控输出结果。
示例
生成一个用户登录函数,不要引入新的第三方库,不要使用废弃的语法,不要在代码中硬编码密码✓ 优势
能有效避免AI生成不符合项目约束的代码,大幅减少人工优化成本,提升编程效率。
AI编程的核心原理
理解这些原理,让你知其然更知其所以然
AI编程的完整链路
AI编程的本质是"AI辅助人类完成编程任务",而非替代人类。让我们看看完整的流程:
核心认知
人工校验和优化仍是关键环节。AI是强大的助手,但最终的代码质量还需要你来把控。
提示词与输出结果的关联原理
提示词的清晰度、约束性,直接决定了AI生成代码的质量。
模糊提示词
"生成一个接口"AI可能生成各种类型的接口,需要你大量修改
精准提示词
"生成一个基于Go Gin的用户登录接口,返回JSON格式"AI直接生成符合需求的代码,减少修改成本
AI代码生成的合理性边界
客观认识AI的优势与局限,建立正确的使用认知。
✓ 优势
- • 高效、快速
- • 能轻松处理重复编程任务
- • 提供多种实现方案
⚠️ 局限
- • 可能存在bug
- • 不贴合复杂业务需求
- • 缺乏业务逻辑考量
💡 正确认知
建立"AI辅助+人工校验"的正确认知,避免过度依赖AI,确保代码质量。
AI的角色定位:从Copilot到顶级执行者
流行的说法是"AI是你的Copilot",这个比喻在日常补全层面成立。但在实际编程实践中,AI更像一个极度服从、无限耐心、但没有内部业务知识常识的"顶级执行者"。
极度服从
AI会一字不差地执行你写的规范,不会主动质疑"这样做合理吗"。
优势
规范写得越准确,执行越可靠
风险
规范有歧义时,AI会选一个"看起来合理"的解释
无限耐心
34次重构、9组联调任务、跨会话的上下文恢复——这些在人类身上需要消耗大量意志力的事情,AI做起来没有摩擦成本。
AI会持续更新进度状态,从不嫌烦,这是处理重复性任务的巨大优势。
没有内部业务常识
AI不知道你们公司的部署环境是什么样的,不知道这个接口上周刚换过版本,不知道"这个交互做成这样用户会抱怨"。
它只知道你告诉它的。这也是生产构建排障花了大量时间的根本原因。
AI的能力边界框架
AI的能力边界不是简单的"能做/不能做",而是根据需求颗粒度选择不同的协作模式。
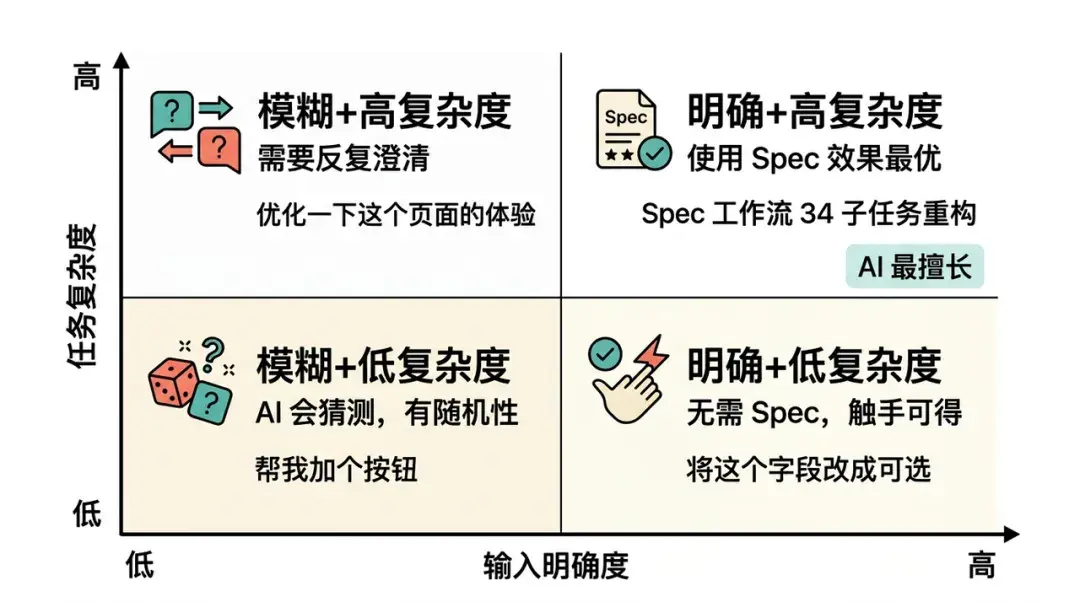
对话框即扫即改
场景:改个文案、修个显隐逻辑、调整CSS间距
策略:直接在AI Chat中对话
理由:沟通成本低于编写规范的成本,AI的即时反馈效率最高
基于Rules或Skills预设规范生成
场景:增加一个标准的CRUD页面、创建一个简单的业务组件
策略:利用预设的Cursor Rules或Skills(如pro-table.mdc)
理由:这类需求有强烈的"模式感"。只要规则定义清晰(如"执行流程:识别场景 → 读取示例 → 生成类型 → 完成UI"),AI就能基于标准化模板高质量输出
OpenSpec深度协作
场景:重构核心逻辑、新增带有复杂业务逻辑的模块、无参考代码的新功能
策略:OpenSpec标准流(SDD)
理由:业务逻辑复杂时,AI极易产生幻觉或需求偏移。通过Spec强制进行"先设计后编码",可以确保AI的每一步都在既定轨道上,且Spec记录了设计的决策过程,对于后期维护价值巨大
上下文关联的核心原理
AI会暂时"记住"当前对话或输入的上下文信息,逐步优化输出结果。
应用场景
适合多步骤编程任务,AI能结合前文信息,保证输出的连贯性和一致性。
例如:先生成函数 → 再优化函数 → 最后补充注释,AI会记住之前的上下文,确保每一步都基于前一步的结果。
Token与上下文窗口的关联原理
Token是上下文窗口的"容量单位",上下文窗口的大小决定了AI可同时处理的Token总量。
⚠️ 超限后果
当你输入的代码、对话内容占用的Token超过了上下文窗口的容量限制,AI就会出现"忘记"前文信息、截断输出的情况。
实用价值
掌握这一原理,能帮你更好地控制成本、规避输出异常。
实战应用场景
将所学知识应用到实际项目中
工具操作中的应用
在使用AI编程工具时,这些概念会帮助你更高效地完成任务。
编写精准提示词
运用提示词工程技巧,明确需求、补充约束、给出示例,让AI生成更贴合需求的代码。
选择合适的模型
根据编程任务选择通用模型或编程专用模型,提升输出质量。
关注Token消耗
了解Token计费逻辑,合理控制输入长度,避免超出额度。
规避上下文限制
估算项目代码是否超限,必要时分批处理,避免"忘记"前文信息。
范式对比中的应用
理解传统编程与AI辅助编程的核心差异。
传统编程
人工编写全部代码,从零开始构建功能。
AI辅助编程
AI生成代码 + 人工优化,大幅提升效率。
核心前提
高质量提示词和AI生成能力是AI辅助编程的核心前提。
工作流实践中的应用
在AI编程工作流中每个环节的应用。
关键环节
管控Token消耗、规避上下文限制是高效开展AI编程工作、提升实操效率的关键。
AI失效的三种模式
经过实践发现,AI Coding的失效不是随机的,而是可归类的。识别这些模式,能帮助你提前预防。
规范真空
表现:任务涉及的领域没有规范约束,AI自行填充"合理默认值"。生成的代码功能正确,但风格/结构偏离团队约定。
发生频率:高(尤其在新功能开发初期)
应对:在CLAUDE.md或code-design中补充对应规范,一次修复,全局生效
信息孤岛
表现:AI掌握的信息是当前会话的快照,看不到系统外的状态。本地正常,CI失败;AI分析每次都对,但解的都是当前暴露的问题。
发生频率:低,但代价高
应对:跨平台、跨环境的依赖要在架构设计阶段提前锁定;环境差异要写成规范前置处理
任务目标模糊
表现:AI把"该问人的问题"当成"执行问题"来解决。用户说"优化一下首页",AI悄悄改了组件结构,而不是先澄清目标。
发生频率:中
应对:Spec工作流的proposal阶段强制要求先描述"Why",避免AI自行填充目标
开发者角色的重构
AI Coding不是让开发者"消失",而是让开发者的工作向上迁移。

规范设计能力成为核心竞争力
能写出让AI可靠执行的规范,价值比能写出同等功能代码更高。
系统性思维变得更重要
生产构建问题的排障经历说明,AI可以帮你解决每一个局部问题,但无法帮你看到真实业务全局。
质量意识前移
过去Code Review在代码写完后进行,现在需要在方案设计/任务执行阶段就介入,而不是等AI执行完再纠错。
值得期待的方向
基于实践数据和经验,后续在以下方向可作深入探索。
规范体系的结构化积累
每次踩坑后补充到CLAUDE.md/rules,形成团队共享的"AI执行约束库"。
下一步可以建立"踩坑→提炼规范→自动追加"的闭环,目前7条规范文件是手动维护的。
MCP工具链的纵向延伸
本项目MCP仅覆盖了接口文档、飞书文档。
后续针对设计稿、测试用例、发布平台、日志平台接入,可以进一步形成完整的AI Coding链路。
多Agent并行开发
本项目开发过程中,发现大型任务执行等待时间较长。
下一步可以尝试多Agent并行生成,同时开发不同功能模块。
🎯 核心与其他
AI Coding的本质不仅仅是用AI写代码,而是用结构化的规范和工作流把不确定性消除在执行之前——AI负责在确定性空间里高速执行,人负责维护和扩展那个确定性空间的边界。
关键要点
- • 规范质量决定执行质量:AI会一字不差地执行你写的规范,规范写得越准确,执行越可靠
- • 根据颗粒度选择策略:小颗粒直接对话,中颗粒用Rules/Skills,大颗粒用OpenSpec
- • 识别失效模式:规范真空、信息孤岛、任务目标模糊,提前预防
- • 角色向上迁移:从"写代码"到"写规范",从"解决问题"到"定义问题"